Természet Világa pótfüzet, Szkeptikus
Lapok, 3. szám, 1999. szeptember
A Biblia kódjáról
HOLBA ÁGNES LUKÁCS BÉLA TASNÁDI
NÓRA
Két évvel ezelõtt jelent
meg Amerikában egy Drosnin nevû újságíró
könyve, s mostanra elért hozzánk is [1]). Odakint sokáig
volt a bestsellerlistákon, és itthon is jól fogy.
Nem is csoda. A könyv ugyanis egyrészt a Bibliáról,
legtöbbször a katolikus terminológia szerinti Teremtés
könyvérõl, protestáns terminológia szerint
Mózes 1. könyvérõl, késõbb még
pontosítjuk, szól, másrészt saját korunk
jelentõs eseményeirõl. A könyv legtöbbünk
számára mellbevágó következtetése
az, hogy a Teremtés könyvében kódolva vannak
bizonyos szavak, frázisok, esetleg rövid mondatok, amelyek
korunkban bekövetkezõ drámai vagy egyébként
fontos eseményeket neveznek meg, mégpedig elég világosan,
nem a jósoknál szokásos homályossággal.
A Biblia kódjának más jóslatokhoz képest
az a jellemzõje, hogy a szerzõ matematikai módszerrel
(egy számítógépes program futtatásával)
fedez fel valami rejtett tartalmat a Bibliában.
A könyv függelékében található
cikkben Witztum, Rips és Rosenberg (a továbbiakban
Ripsék) olyasmit állítanak, hogy a program
alkalmazásával statisztikailag jellegzetes különbségek
adódnak a Teremtés könyve és más hasonló
méretû szövegek közt bizonyos nevek és évszámok
tekintetében. A könyv fõszövegében pedig
az újságíró, a program futtatására
támaszkodva, tartalmukban összefüggõ szavakat talál
egymás "közelében". Az õ állításai
nem statisztikaiak, hanem az így egyedileg megtalált szókapcsolatoknak
tulajdonít jelentõséget. Szeretnénk elkülöníteni
a cikk és a könyv következtetéseit, mivel a matematikusok
állításából nem következik az újságíróé.
Célunk a természettudományokban szokásos
módon megvizsgálni, hogyan használták a statisztikai
módszereket a cikkben, illetve hogyan fogna egy ilyen elemzéshez
olyasvalaki, aki foglalkozik mérési eredmények kiértékelésével.
Ezek után az ilyen statisztikai vizsgálat talajáról
érdemes megnézni, mennyire tekinthetõk véletlennek
vagy sem a könyvben bemutatott érdekes, egyedi állítások.
Lássunk egy példát. Az olvasó talán
emlékszik még, hogy 1995. április 19-én reggel
9 tájban (helyi idõ) az USA Oklahoma államának
azonos nevû fõvárosában valaki felrobbantotta
a szövetségi kormány helyi hivatalainak helyet adó
épületet, amely Murrah-épület néven volt
ismert. Hatalmas pusztulást okozott, a halálos áldozatok
száma 168 volt. Akadt vádlott, és a hosszú
és legjobb tudomásunk szerint megfontolt bírósági
eljárás azzal zárult, hogy a tettes neve Timothy
McVeigh. Mármost a szerzõ, csak az esemény után,
de matematikai módszerével feldolgozva ez esetben a Kivonulás
könyvét (Mózes 2.; Exodus), amely módszert késõbb
részletezzük, a következõ héber nyelvû
szavakat és kifejezéseket találta egymás szomszédságában
(a "szomszédság" jelentését is késõbb
látjuk): Oklahoma; szörnyû, rémisztõ halál;
lesz nagy félelem; Murrah-épület, halál, elpusztítva,
lemészárolva, megölve, darabokra szaggatva; a neve Timothy;
McVeigh; tizenkilencedik nap; a kilencedik órában; reggel;
lesben állt, lecsapott, terror; Koresh halálától
kétévnyire. Csak a legutolsó frázist kell megmagyarázni:
pontosan két évvel korábban fajult tömeghalállá
az FBI fellépése egy szekta ellen, amelyet egy bizonyos David
Koresh vezetett, aki azt állította magáról,
hogy õ a Messiás. Egy elméiet szerint a két
eset összefüggött; ennek tisztázása nem volt
a bírósági eljárás alapvetõ célja.
Nos, ha az eljárás mûködik, haszna nyilvánvaló.
Tegyük fel, hogy elegendõen sok ilyen (már megtörtént)
eseményen igazoljuk, hogy a találatok nem véletlenek.
(A szerzõ szerint ez megtörtént.) Ha tehát valaki
átvizsgálja a Bibliát és talál további
ilyen szövegeket, akkor felkészülhet a bekövetkezõ
eseményekre. Ez ugyan felveti a szokásos problémát
ha egy jóslatot megkapva az eseményt el tudnánk
kerülni, akkor a jóslat nem volna igazi , de e problémát
a görög mítoszok óta vizsgálja az emberiség,
és sokan úgy gondolják, vannak rá válaszaik.
Ha Drosnin eljárása jó, nyilvánvalóan
titkosszolgálatok és más efféle szervek majd
alkalmazzák.
Klasszikus példák rejtett értelemre
A jóslások irodalma több ezer éves. Nem kívánunk
a jóslások életével foglalkozni, de három
példát röviden adunk, hogy lássuk, kb. milyen
"világosnak" kell egy jóslatnak lenni, hogy foglalkozzunk
vele. Az elsõ két példa ókori, és valószínüleg
hiteles; a harmadik újkori, és teljesen dokumentált.
Kr. e. 547-ben Kroisos lüd király már tudta,
hogy meg kell ütköznie Kyros perzsa királlyal.
Hogy biztosabb legyen teendõiben, követet küldött
a delphoi jósdába, hogy átlépje-e a Halys határfolyót.
A jóslatot Hérodotosz õrizte meg. A válasz
szerint ha átlépi, egy nagy birodalmat dönt meg. Vereségét
késõbb úgy magyarázták, hogy a sajátját.
Kr. e. 480-ban a perzsa támadás elõtt Athén
városa szintén jóslatot kért, és teljes
pusztulást sejtetõt kapott. Ezután kért egy
másodikat, amely bizonyos "fabástyák" építését
ajánlotta. Mindkét jóslat szövege (utólag)
bekerült Hérodotosz VII. könyvébe. A szalamiszi
tengeri gyõzelem után bizonyítottnak látták
a jóslatot, mondván, hogy fabástyákon hajókat
értett a Pythia. A jóslatot lehet így is érteni.
1555-ben nyomtatásban megjelent Nostradamus jóslatainak
kötete, tehát a szövegek ellenõrizhetõk.
1559-ben II. Henrik francia király egy barátságos
viadalban véletlenül halálosan megsebesült, és
ezt Nostradamus egy négysorosa igazolódásának
tekintették (ez alapozta meg hírét), de abban nem
voltak nevek. Sokan teljesültnek tekintik viszont egy másik
négysorosát, amelyból most elég két
sor:
"Neufue obturée au grand Montmorency,
Hors lieux prouuéz deliuré a clere peine."
1633-ban kivégezték zendülésért Montmorency
herceget. Elõtte Toulouse új börtönében
(neufue obturée) ült, szokatlan helyen (hors lieux prouuéz)
bûnhõdésre (peine), és a kivégzõ
neve Clerepeyne volt (clere peine).
Drosnin megtalált szavai legalább "annyira jók",
mint a harmadik eset. A szerkezeti hasonlatosság annyiban szintén
megvan, hogy Nostradamus kb. 500 ezer betûnyi terjedelmû szövege
bármelyik része tartalmazhat egy adott idõre vonatkozó
jóslatot, és ugyanez a helyzet Drosninnál hasonló
szövegterjedelem mellett (a Teremtés könyve általa
használt szövege 304 805 betû).
Ekvidisztáns betûsorok
A vizsgálat "õse" Weissmandel prágai rabbi
felismerése a század elsõ felébõl. Ez
nem volt statisztikailag meghatározó, de a számítógépek
elõtti korban nehéz lett volna többet tenni. Vegyük
a Biblia egyik könyvét, hagyjunk el belõle minden szóközt
és írásjelet, és helyezzük át a
betûket valahogyan. Régi tradíció folytán
e permutáció általában olyan, hogy minden n-edik
betût olvasunk el.
Vizuálisan fogatmazva leírjuk a szöveget n betûs
sorokba, majd függõlegesen olvasunk. Ilyenkor néha értelmes
szavak, esetleg nevek tûnnek fel. Ha ezeknek komoIy értelmük
van, hihetjük, hogy ez nem véletlen. Ha ennél objektívabb
vizsgálatra van szükségünk, statisztikai analízist
végezhetünk. Ha így újraolvasva a Bibliát
értelmes szöveget kapunk, felfedeztük a "nyilvánvaló"
szöveg mellett a "rejtettet".
Weissmandel, Ripsék [2] és Drosnin egyaránt
a héber bibliát használta. Ebben több dolog is
szerepet játszhatott, de van egy praktikus haszna is. Minden héber
biblia azonos (ezeket két felekezet használja, az izraelita
és a karaita).
Weissmandel érdekes dolgot vett észre. Mózes bármelyik
könyvének (melyek a héber kánonban a Tóra
részei) elején az 50. betûket összeolvasva megjelenik
a Tóra szó, mintegy jelezve, hova tartozik a mû. Látjuk
majd, statisztikailag mit jelent ez.
Ripsék már, a számítógépek
korában, módszeresebben kutathattak. Számítógéppel
tetszõleges hosszúságú sorokra áttördelhetõ
a szöveg. Ennek során bizonyos sorhossznál pl. a szöveg
egy pontjában két szó találkozott, egyik vízszintesen,
másik függõlegesen (de a szavak csak akkor láthatók,
ha még most is csak minden második betût olvassuk).
Az egyik szó a "mtnyh" (balról jobbra), a másik a
"cdqyhw" (felülrõl lefelé). A héber írás
magánhangzók nélküli (itt most a héber
karakterek helyett a legközelebbi latin hangértékû
betût használjuk, az "y" pl. j-szerû hang, és
mind mássalhangzó), de szakember rájöhet, hogy
az Cidkija júdai király (Kr. e. 598587) neve, míg
a másik Mattanja, trónra lépése eIõtti
neve (2Kir
24, 17). Az elsõ itt igazából Cidkijáhunak
van írva, de így is lehet. A Mattanja hosszú t-je
nincs megduplázva, de nem is köteIezõ. A mássalhangzó-kettõzést
ugyanis lehet a betûbe tett ponttal is jelölni, és azután
e pont el is hagyható.
Mi az esélye annak, hogy ilyen szabályosság "véletlenül"
áll elõ? A méréskiértékelés
folyamatában ezt úgy fogalmazzuk meg, hogy kell egy "nullhipotézis",
azaz pontosan meg kell fogalmaznunk, milyen jelenséget keresünk,
milyen a statisztikai valószínûség a keresett
jelenség nélkül, és ha a statisztikai eredmény
statisztikailag más, a jelenség létezik.
Esetünkben a nullhipotézis nyilván egy második
jelentés nélküli Biblia. Ekkor ha a szöveget nem
az eredeti rendje szerint olvassuk, csak véletlenül jönnek
értelmes szavak, és e véletlen elõfordulások
gyakoriságát ki tudjuk számítani. Ezt kell
összevetni azzal, hogy ténylegesen hányszor jelennek
meg. Ha sokkal többször, akkor valami rejtett szövegnek
kell lennie: ha viszont nem gyakoribb, mindössze a véletlen
hatását látjuk. Ripsék nem az ilyen
találkozások valószínûségén
ellenõrizték a nullhipotézist, hanem egy sokkal közvetettebb
"szabályosságot" sikerült kimutatniuk [2]. A szabályosság
úgy fogalmazható meg, hogy szópárok egy szövegben
átlagban valamilyen értelemben közelebb kerülnek
egymáshoz (valamilyen tördelésben), mint véletlenül
várható. A szópárok: 32 híres rabbi
neve, ill. születési vagy halálozási dátuma.
A "valamilyen értelemben" azt jelenti, hogy a véletlentõl
való eltérést egy bonyolult távolságszabálynát
önkényes statisztikai súlyozással találták
meg. Ez a túl nagy "betûköznél" megjelenõ
szavakat "elnyomja".
A véIetlen találkozásokat sem könnyû
kiszámítani; a személyeknek idõnként
több nevük, többféleképpen írható
dátumuk van. Végül azonban a szerzõk azt találták,
hogy ha a "szavak" távolságát saját bonyolult
eljárásukkal határozzák meg és súlyozzák,
akkor a rabbik életrajzi listájában lévõ
nevek és dátumok átlagtávolsága a véletlenül
várhatónál határozottan kisebb a Teremtés
könyvében; ugyanakkor nagyjából a véletlenül
várható (ennél többet ilyenkor lehetetlen mondani)
hat másik szövegben. Ezek: a Teremtés könyvének
betûit, szavait, bekezdésen belüli szavait és
bekezdéseit véletlenszerûen keverõ szövegek,
Izajás könyve (szintén a Bibliából) és
a Háború és béke héber fordítása.
A két utóbbi szöveg tehát nem mutatja a szerzõk
által talált szabályosságot, az elõzõ
négy pedig azt jelzi, hogy a szabályosság elromlik,
ha a szövegen belül átrendezünk.
Rögtön jelezzük, hegy e statisztikai eredményt
igen nehéz közvetlenül értelmezni. A cikk végén
még érintõlegesen visszatérünk a témára;
a szerzõk szakfolyóiratban publikálták eredményüket,
és a szakmai ellenõrzés nem talált hibát.
Aki nem akarja elfogadni a kapcsolatot a Biblia szövege és
az annak kanonizálása után élt rabbik életrajzi
adatai közt, az hivatkozhat arra a matematikai tényre, hogy
bármely véges számsorhoz végtelen sok olyan
képlet szerkeszthetõ, ami a sor tagjait adja; köznapibban:
gondoljuk meg, hogy minden telefonszám megjegyzéséhez
tudunk ötletes és egyedi "szabályt" gyártani.
Itt most hatalmas nagyságú anyagban igen közvetett,
gyenge szabályosság megnyilvánulását
sejtik.
Történelem a szövegben
Témánk elsõsorban nem a WitztumRipsRosenberg-cikk,
hanem Drosnin könyve. A könyv módszere az, hogy áttördeli
a Bibliát, ezután egymás közelében összetartozó
szavakat lát, és egyrészt ezzel valószínûsíti,
hogy a szöveg kódolt, másrészt úgy gondolja,
hogy ez ad egy módszert a jövõ megismerésére.
Fizikus számára az már mellékes, hogy a kódolást
Isten végezte (Rips) vagy egy idegen szuperlény (Drosnin).
A kérdés az, hogy az értelmes vagy pláne igaz
állítások száma nagyobb-e, mint véletlenül
várható.
Egy példát már láttunk: az oklahomai robbantás
és Timothy McVeigh esetét (a magyar kiadás 106. oldalán).
Másik ilyen példa a Kennedy-gyilkosság (99.
old.) a "meghalni" és "Kennedy elnök" szavakkal függõlegesen,
a "Dallas" szóval pedig ferdén, függõleges irányban
két betûközzel. Akad még néhány
példa a modern amerikai történelembõl.
Más esetek a jelenkori izraeli eseményekkel foglalkoznak,
pl. a Rabin-gyilkosságra vonatkoztathatók a "Jichak Rabin"
(függõlegesen), a "gyilkos, aki gyilkolni fog" (vízszintesen
27. old.); itt jegyezzük meg, hogy ha valami vízszintesen és
kihagyások nélkül jelenik meg, akkor az az eredeti szövegben
van, nem a kódoltban, valamint a szintén vízszintesen,
de nyolc-nyolc betû kihagyásával megjelenõ "Amir"
(Rabin gyilkosa) szavak. Néhány, a könyvben említett
ilyen prófécia határozottan nem történt
meg. Lássunk ebbõl is egy példát. A könyv
74. oldalán a következõ kifejezések jelennek
meg: "Netanjahu miniszterelnök", "bizonyosan megölik", "elvágják
a lelkét", "megölve". (Rögtön megjegyezzük,
hogy a "Netanjahu miniszterelnök" kivételével a többiek
vízszintesen folytatólagosak, tehát az elsõdleges
értelmes szöveg részei, ahol efféle szavak nem
ritkák.) Nos, a miniszterelnök az 1999-es választáson
vesztett, tehát túlélte tisztségét.
A szerzõ utal egy megváltoztatható jövõre,
de gondoljuk meg, hogy akkor mit jelent a "bizonyosan megölik". Úgy
tûnik, az értelmes szövegek egy része hamis; ettõl
még értelmes szövegek, és megvizsgálható,
gyakoribbak-e a véletlennél.
A harmadik csoport "általános" kijelentéseket foglal
magában. Lássunk egyet. A 33. oldalon látjuk: Áv
hó 8. (ez az eredeti szövegbõl, ahol nem igényel
magyarázatot), "a Jupiternek ütközik" (vízszintes,
kihagyásokkal) és "ShoemakerLevy" (ferdén, kihagyásokkal).
5754. Áv 8-án 1994.június 16-án a ShoemakerLevy
üstökös a Jupiterbe ütközött. Ismételjük,
az elsõdleges kérdés az, vajon az áttördelés
után elõtûnõ értelmes kifejezések
gyakonbbak-e, mint véletlenül várható volna.
Jakab király Bibliája és Oprah Winfrey
A könyvre reagált Amerikában 1997 novemberében
David Thomas [3]. Õ a nullhipotézist nem számításokkal
követi, ha nem empirikusan. Veszi a Teremtés könyvét,
de angolul, a Jakab király-verziót (az elsõ hivatalos
angol Biblia). Áttördeli, és például azt
olvassa, "Roswell" (egy ufóeset helye) és "ufó"."Legszebb
példája a Ter 41, 38-46, 40 betûs sorokba tördelve.
Ekkor egy 21 soros részben 16 értelmes szó vagy név
(angol) tûnik fel, ha pedig a ferdéket és a kihagyásosakat
is nézzük, 7 név és 13 további szó
(1. ábra). Ebbõl még mondatokat is össze
tud rakni, amelyekbõl legszebb a "Deion pins nude Oprah", azaz "Deion
leszorítja meztelen Opraht". Van egy ismert Oprah: Oprah Winfreynek
népszerû show-mûsora van (no); hogy Deion milyen tévészemélyiség,
momentán nem tudjuk (egy másik név Leia, aki
természetesen Organa hercegnõ a Csillagok háborújából),
de az üzenet érdekes. (Lehet, hogy nem teljesül, de ilyent
az elõbb már láttunk Netanjahuval kapcsolatban is.)

1. ábra. Jakab király Bibliájának egy
kis része 40 betûs sorokra tördelve, angol nevekkel és
értelmes szavakkal. A szürke alapon vastag betûk függõlegesen
lefelé olvasandók. A fehér alapon vastag betûk
felfelé olvasandók, az egyéb jelek ferdén,
kihagyásokkal. D. E. Thomas példája
Thomas következtetése az, hogy elég nagy szövegbõI
seregével bukkannak fel értelmes szavak és mondatok;
mi kiválogatjuk azt, amire ráismerünk, és örülünk
neki. Meglehet, de azt õ sem mutatja meg, hogy a Jakab király
Bibliájában (ami szintén lehet kódolt) nincs
ilyen gyakrabban vagy ritkábban, mint másutt. Ezért
mi megvizsgáltunk egy garantáltan nem transzcendens mûvet,
amely kb. olyan hosszú, mint a Teremtés könyve, magyar
nyelvû, tehát a nyelvi sajátságok kézben
tarthatók, betûkészletét úgy redukáltuk,
hogy hasonlóan többértelmû legyen, mint a héber,
tiszta mássalhangzós írás, a jelenkori magyar
történelemre kérdeztünk rá, és egyértelmûen
számítottuk a nullhipotézis találati valószínûségét.
"Utolérni és felfalni..." meg a magyar NATO-tagság
Kiinduló szövegünk Holba Ágnes kiadatlan
regénye, melynek címe Utolérni és felfalni...,
és meglepõ módon egy kutatóintézeti
fizikus viszontagságait írja le. A mû szövege
1987-ben rögzült (1990 elejérõl származó
pozitív lektori vélemény Göncz Árpád
írószövetségi elnöktõl). A kézirat
használata melletti három komoly érv:
1. már számítógépben van;
2. hossza (351 355 betû) hasonló a Teremtés könyve
héber verziójáéhoz;
3. annyira távol áll bármely emberfeletti befolyástól,
amennyire csak lehet.
Ezek után a magánhangzókról minden ékezetet
eltávolítottunk, a szóközökkel és
írásjelekkel együtt. Ezzel az írás hasonlóvá
vált "homályosság" szempontjából a héber
mássalhangzós íráshoz. Ezután egyrészt
a magyar szövegben 26 különbozõ betû marad,
azonban a q, w és x ritkasága miatt gyakorlatilag csak 23,
míg a héber szöveg 22 betûs. Másrészt
a nem jelölt
magánhangzók a héberben általában
nem a szótõ, hanem csak a nyelvtani szerepet jelölik.;
magyarban a magánhangzó nélküli írás
sokkal érthetetlenebb (többértelmû) volna, de
a magánhangzók ékezeteinek hiánya szintén
csak mérsékelt összetévesztéssel jár.
Egy példa: "dorombol" és "dörömböl" egyaránt
"ütemes mély hangot ad".
Most már rá lehet keresni kiválasztott szavakra.
A vizsgálatra a "NATO", "Horn" és az "Orbán" neveket
választottuk. Ez volt ugyanis (eddig) 1999 nagy magyar történelmi
eseménye: elõször a NATO-csatlakozás, utána
pedig szinte rögtön egy fegyveres konfliktus. Viszont szemben
az eddigi mûvekkel, mi a véletlen találati valószínûségét
is meghatároztuk.
Betûk gyakorisága
Minden nyelvben más és más a betûk elõfordulása;
ezért egyik nyelven végzett statisztikai elemzés teljesen
félrevezetõ lehet a másikon. Drosnin nem ad héber
statisztikát. Thomas kettõt is ad angolul: egyrészt
a Jakab király Bibliájáét, másrészt
egy vallási ügyben hozott legfelsõ bírósági
végzését. Ebbõl rögtön kiviláglik,
hogy a h több mint kétszer olyan gyakori a Bibliában,
mint a jogi szövegben, tehát minden szöveget önmagából
kell ellenõrizni. Magyar szövegünk betûgyakoriságát
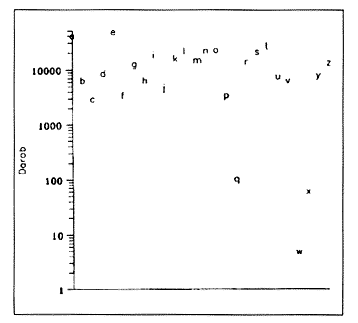
a 2. ábra mutatja.
 |
 |
2. ábra. A betûk gyakorisága a magyar szövegben
(a függõleges tengely logaritmikus) |
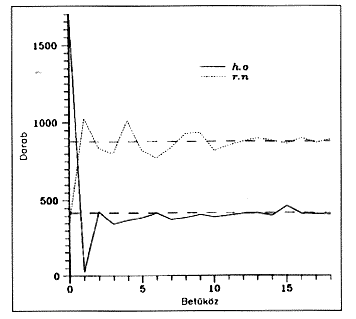
3. ábra. Két betûpár elõfordulása
a sorhossz szerint |
Következnek a kétbetûs kombinációk.
A 3. ábra két ilyen kombináció, az "n.
a" és az "r. b" gyakorisága, attól függõen,
hogy a pont helyén hány betûs ugrás van. A szaggatott
vonal lenne a véletlen elõfordulás.
A következõt láthatjuk. A magyar nyelvben (de legalábbis
az Utolérni és felfalni... nyelvében) mássalhangzó-magánhangzó
kapcsolat általában akkor a legvalószínûb
, mikor szomszédosak. Néhány betûköz után
a gyakoriság gyakorlatilag már véletlen kombinációs
valószínûség. (A statisztikához meg lehetne
határozni az elméleti hibahatárt is, de láthatóan
felesleges.) A mássalhangzó-mássalhangzó szomszédság
viszont nem gyakori; ilyen a véletlen gyakoriságnál
kevesebb van, viszont egy betûhellyel odébb meg több.
A lépésköz növelésével azután
már itt is beáll a véletlen gyakoriság.
Ha tehát legalább tízbetûs sorokba tördeljük
a szöveget, a függõlegesen olvasható szövegnek
már semmi köze nem lehet az eredeti "finomszerkezethez". Ezek
után a 10-es és a 100-as sorhossz között minden
tördelésre megkerestünk három szót.
Az elsõ természetesen "nato". A másik kettõhöz
(politikai) magyarázat szükséges. A mû szerzõje
állítja, hogy nem volt szándéka a szövegben
NATO-ra vonatkozó utalásokat elrejteni. A szöveg 1987-es
rögzítésekor a NATO-csatlakozás még nem
volt idõszerû. Elõször formálisan Antall
József kormányzása idején Horn Gyula
vetette fel 1990 második felében, de korainak minõsítették.
A csatlakozási kérelmet hivatalosan Boross Péter
miniszterelnök terjesztette be 1994-ben, a csatlakozási
folyamat szépen haladt Horn Gyula alatt, de csak Orbán
Viktor miniszterelnöksége alatt lettünk tagok.
Mivel az Antall és a Boross hatbetûs, csak a "horn" és
"orban" szavakra kerestünk rá. 10-es és 100-as sorhossz
közt az alábbi elõfordulásokat találtuk:
nato 1135-ször fordul elõ,
horn 91-szer fordul elõ,
orban 11-szer fordul elõ.
Az eredmény legközvetlenebb értelmezése kb.:
a NATO-csatlakozás ügye a mai magyar sors lényeges kérdése,
amire vonatkozóan sok kijelentés van kódolt szövegekben;
és ebben Horn szerepe kb. nyolcszoros volt Orbánéhoz
képest. (Egy ilyen állítás nem a priori lehetetlen,
mivel az 1990-es parlamentben Horn a külügyi bizottság
elnöke volt.)
A nullhipotézis végigszámolása viszont érvényteleníti
az értelmezést. A kódolás teljes hiányában
az alábbi eredményt kellene látnunk (második
oszlop):
|
Találat, db |
Számolt
véletlen elõfordulás |
| nato |
1135 |
1143 |
| horn |
91 |
95 |
| orban |
11 |
11 |
Anélkül, hogy az elméleti hibahatárt számítanák,
alighanem mindenki elhiszi, hogy a véletlen találatok történtek
meg a szokásos véletlen ingadozással.
Az lenne tehát kódolás, ha valamelyik szó
gyakrabban/ritkábban jelenne meg. A mostani eredményt
értjük. Egyszerûen "nato" azért gyakoribb,
mint "horn", mert az elsõben nincs három mássalhangzó
és mert az "a" gyakori; és "orban" ritkább, mint "horn",
mert egy betûvel hosszabb. (Ezért nem kerestük Antallt
és Borosst; hosszabbak és belõlük legfeljebb
egy várható.)
Marad a kérdés, milyen gyakoriak a "találkozások",
pl. "nato" és "horn" közel, de mindenesetre egy belátható
oldalon. Erre nem kerestünk rá, ugyanis igen sok véletlen
találkozás várható.
A normál gépelt oldal kb. 2000 betû. Ekkor (nem
állva meg 100-as sorhossznál) oldalanként kb. 35 "nato"
és kb. három "horn" jut véletlenül. Normál
tördelésnél az egyik átlag egyszer soronként,
a másik vagy kétszer oldalanként; kizárt, hogy
valahol ne metszenék egymást.
Hány betûs Dallas?
Térjünk vissza Drosninhoz; a magyar szövegbõl
sokat tanultunk. Kritikánk lehetne, hogy a magyar szövegben
csak rövid szavakat találtunk gyakran, míg Drosnin hosszabbakkal
is foglalkozott. De ez legtöbbször nem is volt így. A
sémi nyelvek alapvetõ tulajdonsága: a régi,
eredeti szótövekben a mássalhangzók száma
általában három [4]. Képzett vagy összetett
szavak lehetnek négy vagy öt mássalhangzósak,
de az ritkább. Valóban, a 37. oldalon az "öldöklés"
négy betû. A 45. oldalon
"elektromosság" négy betû. A 67. oldalon "megválasztva"
négy betû. És így tovább. Amikor egy
héber kifejezés lényegesen hosszabb, pl. egy teljes
név, akkor ritka is. Pl. a meggyilkolt miniszterelnök, Jichak
Rabin neve 8 betû így: "ychqrbyn" (felteszem, hogy ez valóban
a helyes alak), és az egész Teremtés könyvében
csak egyszer jön elõ. Egy nyolcbetûs szó hasonlóan
ritka lenne a magyar szövegben is, csak Jichak Rabin magyarul már
11 betû.
Lássuk az angol neveket. Kennedy neve (98. old.) "qndy", és
hadd fejezzük ki kételyünket azzal szemben, hogy e névben
a mély hangú k-változat szerepeljen. Az európai
nyelvek általános tulajdonsága, hogy magas hangokkal
magas k-variáns jár; a sémi nyelvekben ez nem kötelezõ,
és azért van k és q [5]. A "Kennedy" név írskót.
Más szóval ez szerintünk nem is Kennedy. A környékén
állítólag ott van Dallas, halála helye. Így:
dalas (a négy s-hangból samekkel). Nos, Dallast le lehet
így is írni.
Ezen kívül azonban számtalan módon: 1. a samek
helyett legalábbis sin is állhatna, 2. el lehetne hagyni
az elsõ a-t, mert az az angolban magánhangzó (Kennedynél
mindkét e hiányzik). 3. el lehetne hagyni a második
a-t. 4. lehetne két 1-et írni, 5. lehetne visszafelé
írni, más szavaknál van is ilyen példa. Ez
25 = 32 lehetõség, tehát "Dallas" 32-szer
gyakrabban várható, mint gondolnánk. Még furcsább
a "McVeigh" név írása (107. old.), a "mqwwyy" bárki
lehet.
Ismételjük: ha többféle írást
is el tudunk képzelni egy névre, megugrik a "nevek" megjelenésének
valószínûsége, véletlenül is várhatók
nevek és szavak. A magyar anyagon szerzett tapasztalatainktól
azt várjuk, hogy Drosnin szavai és nevei megjelennek a nullhipotézis
esetén is (amit õ még nem számolt ki), és
azt mondhatjuk, hogy egy alapos számszerû becslés nélkül
minket nem tudott meggyõzni arról, hogy amit talált,
nem véletlen (ahogyan mi legalábbis valószínûsítettük,
statisztikával többet nem tudunk, hogy a magyar szövegben
a "nato", "horn" és "orbán" betûsorok tisztán
véletlenek).
Legalábbis éppen annyi van, mint véletlenül
lenne. Ilyen vizsgálatot, legalábbis a valódi héber
és jiddis szavakra és nevekre, meg lehetne csinálni
a héber Teremtés könyvén is; mi csak azt mondjuk,
hogy ezt könyvében Drosnin nem csinálta meg.
És amit szintén nem vizsgált: egy-egy kiragadott
mátrix betûtengerében nincs kontroll arra, hogy más,
esetleg ellentétes jelentésû üzenetek nincsenek-e
kódolva. Pl. a most kimutatott statisztikai eredmények megengednek
az állítólagos "Qennedy" (98. o]d.) közelében
akár egy "túlélni" szót is, amely héberül
nyilván szintén hárombetûs.
És még a keresztezõdések állítólagos
ritkaságát kérdõjelezi meg két megjegyzés.
Sokszor ami keresztez, egy három-négy betûs eredeti
héber szó: a magyar szöveg vizsgálatakor láttuk,
hogy ilyen rövid szavak teljesen véletlenül is nagyon
sûrûn vannak. A másikat a 98. oldallal szemléltetjük.
Itt "találkozik" az "Oswald" (már ha az) név a "mesterlövész",
és a "gyilkos aki gyilkolni fog" kifejezésekkel. De mindkét
utóbbi vízszintes, azaz a Biblia elsõdleges szövegébe
tartozik, ahol csak értelmes szavak lehetnek, és efféle
jelentésû szavak gyakoriak. Ráadásul a "mesterlövész"
természetesen csak három betû.
Epilógus
Befejezésként két megjegyzés. Az egyiket
nyilván igényli az olvasó; a másikat talán
nem, de megtehetné.
Láttuk, hogy Ripsék [2] igazolták, hogy a Teremtés
könyve szövegének van valami sajátos jellegzetessége.
Be kell vallanunk, hogy nem tudjuk, mi; a statisztikus próba
olyan bonyolult, hogy lehetetlen pontosan megmondani, mit mér. De
tapogatózni tudunk.
A szerzõk szerint a szövegnek valami titokzatos módon
köze van 32 rabbi adataihoz. Nem azt mondjuk, hogy ez lehetetlen (más
kérdés, hogy jelen fizikai elméleteinkkel ezt nehéz
lenne megmagyarázni). Egyszerûen csak azt mondjuk, hogy ezt
akarják bizonyítani, de az addig nem történik
meg, amíg "egyszerûbb" lehetõségeket nem néznek
végig. Mármost áttanulmányozva a [2] cikket,
úgy látjuk, hogy a statisztikai próba erõsíti
a csak néhány betûközre lévõ kapcsolatokat
(azzal, hogy a távoliakat elnyomja). Ekkor viszont nem lehetetlen,
hogy a nyelvi "stílusból" valami még átmegy
a próbán. (Ennek elkerülésére kezdtünk
a magyar anyagnál tíz betûköznél; a 2.
ábra jelzi, hogy ilyen távolságban a betûk
gyakorlatilag nincsenek egymással összefüggésben.)
Ha a hatás innen jön (és innen jöhet),
akkor persze az összekevert betûjû Teremtés könyve
más lesz; a Háború és béke pedig modern
regény, héber fordításának egészen
más a szókészlete stb. Marad még Izajás
könyve. De Izajás szövege mintegy 600 évvel késõbbi,
mint Mózes élete. Nem ártana valamit tudni, mikor
is fejezték be Mózes öt könyvének szerkesztését,
csak annyi biztos, hogy Jósiás király
alatt, mondjuk, Kr. e. 620-ban már mind az öt könyv megvolt.
Mindez tudományos elméleteket meg vallásos hitet
érint, ahol fizikusok meglehetõsen idegen talajon mozognak.
De az biztos, hogy Mózes 1. könyve átlagban régebbi,
mint Izajás. 600 év alatt pedig a nyelv és a stílus
lényegesen változik. Legalább a betûgyakoriságokat
össze lehetne hasonlítani, valószínûleg
alapvetõen különböznének, de e vizsgálatnak
nyomát sem látjuk.
Még egészen futólag érinteni kell ama kérdést,
mikori szövegállapot van Drosnin kezében. Õ ugyanis
arra gondol,
hogy az "eredeti" és "emberfölötti származású"
szöveget vitte gépébe, amely 3200 éves (86. old.).
Nos megint vallásos hitet is érinthet, de , ha valaki
világi síkra lép tudományával, nem követelheti
meg olvasóitól vallási alapfeltevések vita
nélküli elfogadását. A fölösleges részletek
nélkül a mai héber kánon egyetemességét
biztosan tudjuk igazolni 1500 évre viszszamenõleg, de talán
1900 évre is [8]. Korábbról többféle szövegrõl
tudunk, bár ezek a "nem kódolt" tartalomban nem nagyon különböznek.
Ránk három független szöveg maradt vallási
használatban, két nyelven, és a holt-tengeri (qumráni)
tekercsek egy negyediket képviselnek. Van a "héber Biblia",
amelyet két vallás használ, az izraelita és
a karaita (ezt használja Drosnin), fordításokban pedig
sok protestáns felekezet. Létezik viszont egy másik
héber szöveg, amelyet a szamaritánus vallás
használ. Azonkívül a Septuaginta, amely görög
nyelvû, de láthatóan más héber eredetit
használt (Mózes l. könyvét jóval Qumrán,
tehát a Kr.e. I. század elõtt fordították,
Kr. e. 200 tájékán). A qumráni szövegek
egyszer egyikhez, másszor másikhoz állnak közel,
és tudunk Kr. u. 100. körül szövegegységesítõ
munkáról a jamniai teológiai fõiskolán.
Lehet, hogy a szöveggondozás épp az õsit állította
helyre, de ezt a független qumráni kézirat nem igazolja.
Kódolt szöveg megjelenését pedig már kis
változások is megakadályozhatják.
IRODALOM
[1] Eredeti: M. Drosnin: The Bible Code. Simon & Schuster, 1997.
Magyar kiadás: A Biblia kódja. Budapest, 1999.
[2) D. Witztum E. Rips Y. Rosenberg: Statistical Science 9, 429
(1994)
[3] D. E. Thomas: Skeptical Inquirer, 1997 nov./dec. 30. old.
[4]Anral L. Csongor B. Fodor I.: A világ nyelvei. Gondolat,
Budapest, 1970.
[5] M. Pei: Szabálytalan nyelvtörténet. Gondolat,
Budapest, 1966.
[6] Iványi T.: A sémi írások. In: Bevezetés
a magyar õstörténet kutatásának forrásaiba
III. Szerk. Hajdú P Kristó Gy. Róna-Tas
A., Tankönyvkiadó, Budapest, 1980. 49. old.
[7] Bárczy G.: A magyar nyelv életrajza. Gondolat, Budapest,
1966.
[8] Vermes G.: MTA Judaisztikai Kutatócsoport Értesítõ,
6. sz. 1992. június.